事件风暴
什么是事件风暴?
事件风暴(Event storming)是一种头脑风暴形式的需求分析和领域建模的活动,由 Alberto Brandolini 发明。和其它的建模活动相比,它的显著的区别在于它以领域事件作为分析和建模的切入点,这也是它的名称的由来。
下面这种图展示了事件风暴的建模组件。 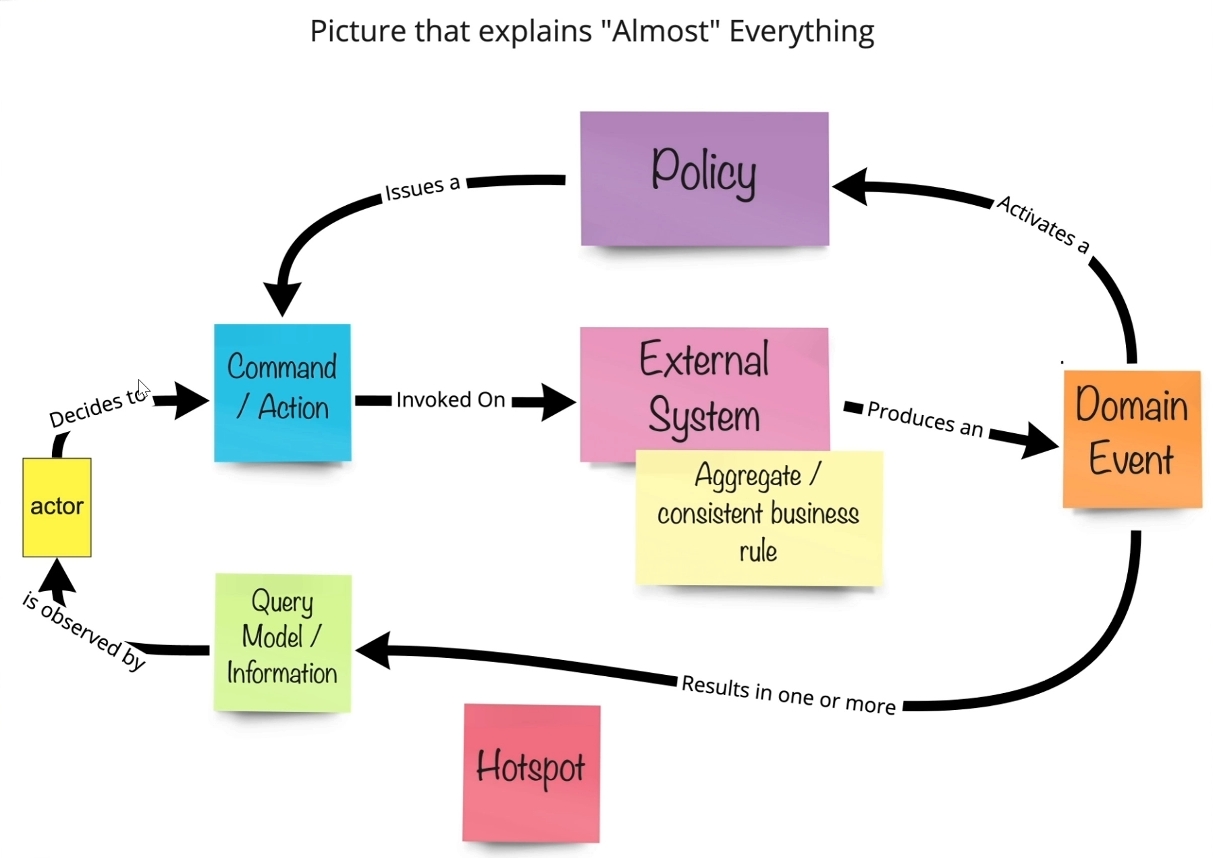
事件风暴必须用来做DDD建模吗?
不是的。可以把事件风暴当成一种分析工具,帮助研发甚至领域专家自己去学习领域知识。零件风暴中的领域事件、领域命令、Policy、Actor、ReadModel都是让非技术人员容易理解的概念。非技术人员可以从这些模型中收益。
如何建模Policy?
Policy表达这样的语义:“每当某个事件发生的时候,要执行某个命令”。它体现了存在于业务中一些自动化的策略或者规则。比如,每当用户下了订单时,要给订单里的商品的商家发送一个提醒。
有时候,这些自动化的策略规则并不是像聚合内部内部那样存在更强的必然性。以前面的例子来说,不给商家发送提醒,也是可以的,之所以要发送,只是当时的一种商业策略。但是对于聚合来说,比如“每次用户删除购物车里的一个商品,购物车总金额都要减去该商品的金额”,这种规则就是有很强的必然性的。
有时候,这些自动化的策略体现的是多个对象间的协作,而我们又不希望这些对象间产生直接的关联。比如前面的例子,负责下订单订单和负责通知商家的对象是两个对象,让这两个对象直接依赖对方,似乎不是一个很好的方式,所以才引入Policy对象。
Policy对象是无状态的吗?是领域服务吗?
大部分情况下,Policy都是无状态的,是一种领域服务。如果在接收到领域事件后,需要根据状态判断执行哪些命令。这个时候,可以把这个职责委托给一个聚合完成。如果一个聚合专门负责这样的自动化流程,你这个聚合又被称为流程管理器(process manager, SAGA)。
区分外部系统的标准是什么?
这是一个相对的视角。在建模初期,我们可以把所有不是当前系统的所有其它系统都看成是外部系统。随着建模深入,如果需要拆分成多个限界上下文,那么不同上下文间需要隔离,从一个上下文的视角看,别的上下文也是外部系统。从实现角度开,当前领域模块代码以外的,别的系统的代码,不管用不用DDD,都是外部系统。
外部系统也可以接收命令发布领域事件,那它不是和聚合一样了吗?
它和聚合最大的不同是,最终它不需要被我们实现,它是由“外部”实现了。我们应该投入更多的精力在聚合上,那些确定是外部系统完成的功能的,就假定他们一定可以完成,不用投入过多了。或者说,在你看来的外部系统,是别人的聚合,别人会去负责做它的聚合的设计。
使用事件风暴对领域建模相对于别的领域建模方式有什么优势?
简单直观
事件风暴支持业务专家、开发人员、产品经理等不同角色共同参与。
对于事件风暴中的各个元素(如 命令、事件等),即使非技术人员也能很快的理解。有利于消除技术与业务之间的隔阂。
发现隐藏的问题
通过团队讨论和事件梳理,能够暴露出业务流程中的隐性问题、瓶颈或不一致之处。
通过梳理领域事件,团队可以从全局视角理解业务流程,识别上下游依赖关系和潜在问题。
方便迭代
- 事件风暴是一种高度迭代的过程,允许团队快速调整和完善模型,适应业务需求的变化。
更聚焦于问题域
先事件命令,再聚合,由事件命令推导出聚合。事件命令直接反映了系统该如何解决问题,而聚合是根据它们推导出来的。这使得建模聚合的时候,更容易聚焦在解决问题上。如果建模开始就做聚合的设计,往往容易把聚合当成数据实体,只关数据满足解决问题,但是忽略了系统的运作的行为。
更易于实现
只要用代码实现了事件风暴建模出来的事件命令聚合等对象,就自然得到能解决需求的系统了。相比于别的建模方法,过于聚焦在聚合、实体、值对象的数据上,忽略了事件命令这些行为,容易遗漏很多业务功能,往往在实现的时候要用领域服务去补充很多遗漏的业务功能,容易导致贫血模型。
支持创新和改进
事件风暴不仅仅是建模工具,还能激发团队对现有流程的改进和创新思考。
事件风暴适用于哪些场景?
一般具有如下特征的业务场景,适用事件风暴:
- 多角色,多用户
- 长流程
- 人机多交互
大部分商业应用都是属于这一类的。这类系统的复杂性,一般体现在这些交互和流程上,相对的,每次交互的算法可能相对简单一些。这种场景可以分析出很多事件命令,从而使用事件风暴比较有效。
相反的,可能很难找出来多少事件命令,复杂性都在某个命令执行的算法上了,则不太适合事件风暴。
对于事件风暴的改进
原版的事件风暴,更着重于多人头脑风暴快速掌握问题域,我们在此基础之上加上更加详细的工程化的可复制的思路,来帮助如何建模出可实现的模型。
这里主要提出了三个目标:
- 事件命令完备
- 所有的事件都有来源
- 所有命令执行过程中需要的信息都能来自于当前命令或者历史事件
- 所有读模型都能通过领域事件构建出来(考虑Query)
- 聚合完备
- 所有事件都被分配到某个聚合上(外部系统负责的事件除外)
- 所有聚合的状态都可以通过其历史事件重建(事件溯源)
- 所有命令的功能都可以被分解后由聚合或领域服务完成
- 聚合优化
- 聚合不会太大,导致出现性能问题
- 聚合不会太零碎,导致高耦合被泄露到外部,引发贫血模型,缺少抽象和封装
实现了事件命令完备,这个领域模型在逻辑上就是自洽的满足需求的。实现了聚合完备,在不考虑技术限制的情况下,这个领域模型就是可以被实现的,并且满足需求的。
因此我们将事件风暴建模总体化成三个阶段,来达成这个三个状态,如下图: 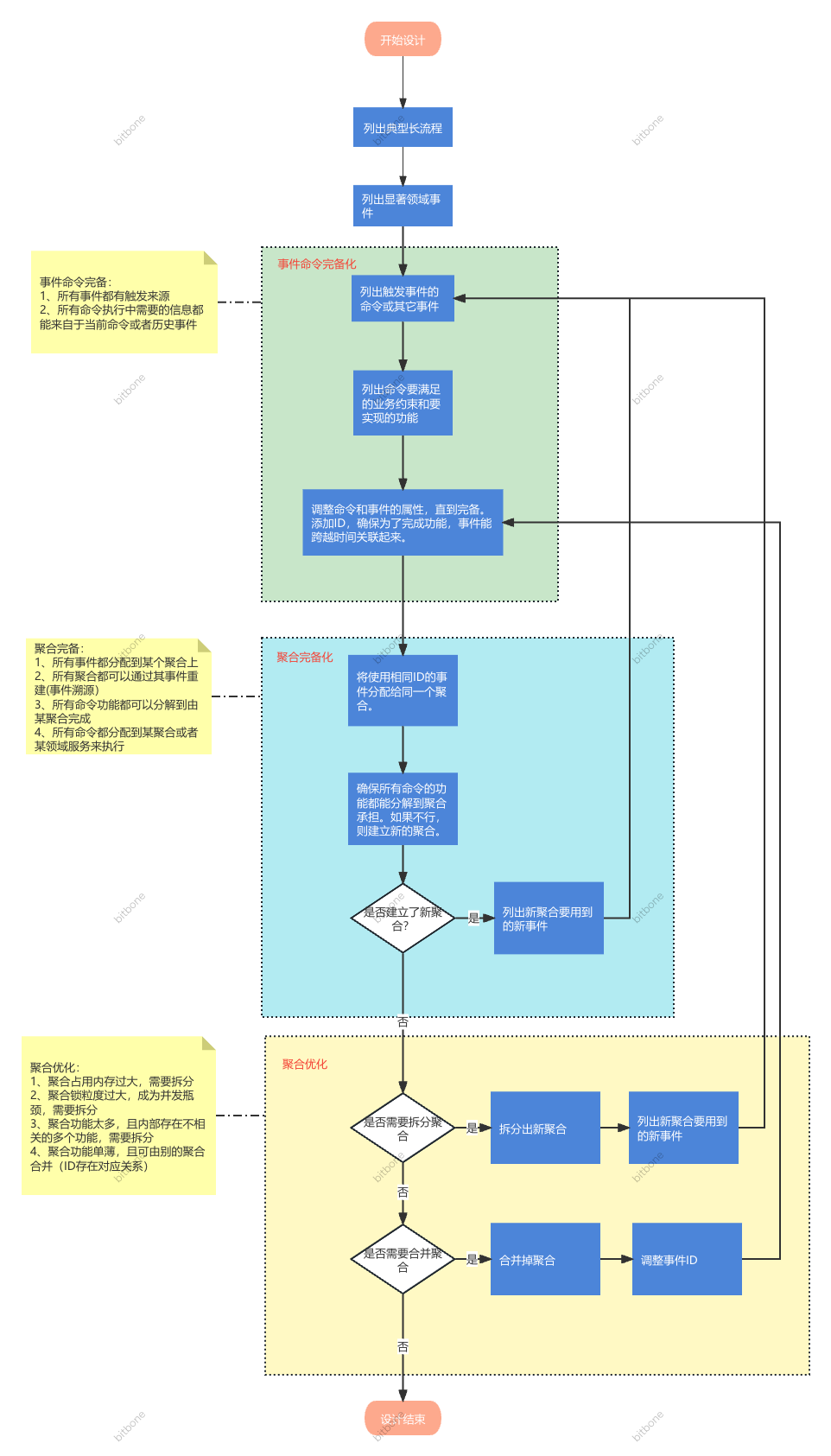
必须要按照这个步骤做吗?我可以跳着做吗?
本质上,只要最终达到了聚合优化,满足需求,怎么做都可以。但是为了避免由于“想当然”导致出现遗漏等,最好还是按部就班的做。多人协作的时候,尤其是按照步骤来更容易协同,否则大家思维太跳跃,难以协同。
如果你已经经验丰富,而且已经对问题域很熟悉,而且是一个人做,那么直接到产出聚合也可以,不过还是要自己审视一下,是否真的完备了自洽了。
必须每个步骤都一次性做好吗?
不一定,你可以迭代的来做。可能做到后面,发现新的问题,再回去做事件命令。不追求一次性搞定。