命令和查询职责分离(CQRS)
命令和查询职责分离,英文名 Command and Query Responsibility Segregation。这种架构风格中,把业务需求分成查询类和命令类两种,查询类不会引起业务变更,命令类会引发业务变更,在系统层面,将负责实现这两类功能的代码分拆到不同的模块里。DDD实践中使用CQRS时,让领域模型主要满足命令类的业务需求,将查询类,尤其是复杂查询类的需求交给领域模型外的读模型去单独满足。
标准的CQRS架构如下图: 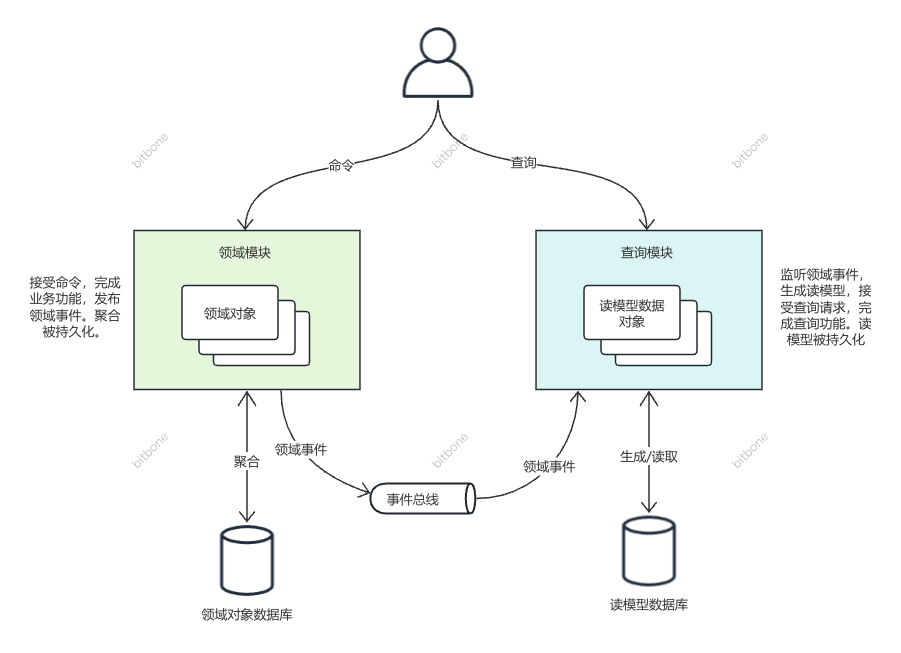
CQRS给DDD实现带来什么好处?
让领域模型不用承担复杂查询的责任,大大降低领域模型建模和实现的难度。
在典型的系统中,命令类和查询类功能存在巨大的差异。
命令类功能往往需要较少的领域对象参与其中,而且这些对象往往互相间存在协作关系,共同完成业务功能。由于这些业务功能导致领域对象发生了变更,还需要把它们再次持久化,给下次使用。
查询类的功能,只需要读取数据,转化成需要的格式,返回给用户即可。这些数据,都算不上对象,它们没有行为,被载入到内存后,互相间没有交互,也不会发生变更。 困难在于如何找到这些数据,如何高效的找到这些数据。这里涉及到查询条件的多变,数量检索的效率问题。
假如聚合同时承担上面两类责任,就面临着矛盾:
- 冗余:实现命令类功能需要尽量不冗余数据,而为了查询效率,又必须冗余一些数据
- 为了更容易实现命令类功能,聚合内相关的对象要整体读取,而为了查询效率,经常只查询部分用户关心的数据,不同角色的用户需要看到的数据还不一样
- 为了确保业务数据的一致性,命令类功能更倾向于使用数据库实现,而为了查询能力和效率,经常需要使用redis elastics-search 等等多种存储方式混合存储
因此,让聚合同时承担查询责任,是很困难的。采用CQRS,让聚合彻底不用管查询责任了,让建模和实现更容易。
什么情况下使用CQRS?
当有复杂查询需求的时候,必须采用CQRS。复杂查询,简单来说就是无法通过简单重用聚合的数据存储来实现的查询功能,包括但不限于
- 查询条件复杂,需要冗余数据做索引
- 高性能查询,需要把数据同步到一些高性能查询设施里
- 多数据源整合后才能满足的查询
- 复杂的数据分析报表等
即使不存在复杂查询,采用CQRS也可以让领域模型更干净,让查询和命令的代码分开来,整体架构更整洁,也是值得的。
大部分稍微复杂点的信息管理类的应用,都会存在需要CQRS的情况。
如何确保读模型一定能够通过领域事件生成出来?
因为读模型是人为设计出来的,它一方面要满足用户查看数据的需求,一方面又要确保能够通过领域事件生成。如果不能通过领域事件生成,那说明在设计领域模型的时候,漏掉了某些东西,要去调整领域事件,对应的调整命令聚合等,直到整体都能够逻辑自洽。
使用事件风暴一定得用CQRS吗?不用CQRS也要设计读模型吗?
事件风暴处于建模阶段,在这个阶段已经采用了CQRS的思想,但是并没有要求最终一定得采用CQRS的实现,因此即使不使用CQRS来实现,在事件风暴过程中也要去设计读模型。
当然,大部分情况下,既然已经按照CQRS,做了设计了,不如在实现的时候直接采用CQRS。
领域模块里要查询数据,必须得通过读模型来查询吗?
不是的。领域模块里,是可以直接读取聚合的,没有必要也不可能都通过读模型去查询数据。领域模块的聚合的信息,才是业务唯一真实一致的业务数据,不应该依赖外部。
某些特殊场景,为了性能优化,或者要使用一些复杂查询,这些在领域模块里的聚合上完成不了,那么是可以妥协一下,通过依赖翻转,使用外部的读模型来实现。
是不是所有的查询功能都必须用读模型?不能查询聚合来满足查询需求?
不是的。一些简单的查询,重用查询聚合就可以满足的,那就重用也没有问题的。但是要切记,这只是恰好查询需求能够被聚合的查询给满足了而已。不能因为聚合的查询不满足了,就去为了查询需要而修改聚合,污染了领域模型。出现这种情况的时候,应该过段放弃使用聚合来实现查询,改成用读模型。
CQRS就是读写分离?
不是。读写分离,是从数据的角度来看的,一般用在数据库架构上。CQRS是从业务功能的角度来看的。实际上,领域模块(实现命令类功能),也会有数据查询;查询模块(实现查询类功能),也会有数据写入,因为要构建读模型。
必须监听领域事件异步生成读模型吗?
不一定。这是标准CQRS模式,但是并不是唯一的CQRS模式。CQRS本质的目的,是在把负责两类职责的代码给分开,只要代码分开了,为了开发便利性,采用非标准模式是可以的。
不监听领域事件,持久化聚合时生成读模型
如果读模型和聚合的持久化数据差异不大,只需要在持久化聚合的时候,额外多冗余一些数据就可以完成,那么可以采用这种方案。只需要在仓储实现的代码里,增加额外写入读模型数据即可。
这总方法实现最简单,读模型写入和聚合的持久化在一个事务之内,保证了一致性,还不需要监听领域事件。但是这种方法也存在非常大的局限性,复杂一点的读模型,可能就无法通过聚合的数据推断出来,必须要监听领域事件,甚至是别的聚合发出的领域事件了。
同事务监听领域事件,生成读模型
在命令执行的数据库事务内去监听领域事件,生成读模型。一样可以通过数据库事务,保证聚合和读模型的强一致。这种方式实现起来也很简单,简单的同步的观察者模式就可以胜任。建议起步的时候,采用这种方式,若以后出现了生成读模型占用时间过长,或者要监听远程的领域事件的情况,再考虑改成异步的或分布式的方式。
本地监听事件异步生成读模型
依旧在同一个进程内生成读模型,但是是在命令执行完成后,再监听领域事件去处理。这种方式缩短了命令执行事件。由于读模型和聚合的持久化不在一个事务内了,需要做最终一致性,开发成本会更高。 这种方式已经是标准的CQRS模式了。
远程监听事件异步生成读模型
再分布式系统中,允许专门有一个服务,负责监听多个服务的领域事件,生成读模型。要引入消息队列,做好最终一致性,开发成本较高,换回来最高的灵活性。
异步生成读模型,导致用户不能立刻看到变更结果怎么办?
首先考虑是否可以不异步去生成读模型,改成同步的在一个数据库事务的方式。只要总体响应时间可以接受,同步的方式更加简单。
其次,考虑在产品设计上规避。比如用户操作后,界面上提示数据有延迟。
再次,在前端或者服务端做一个同步机制,用操作完后,必须等后续的任务执行完,才告诉用户执行完成。这种方式,开发起来比较复杂。
如何确保读模型和领域对象的数据一致性?
性能够用的时候,采用在同一个数据库事务内修改的方式,使用强一致性。如果不能使用强一致性的办法,那只能最终一致性了,做好重试,人工介入。
报表类的功能算是查询类功能吗?可以用CQRS吗?
算,可以用cqrs。比如,根据报表需求,通过领域事件计算出实时或者离线的数据。
读模型必须和聚合对应吗?
不需要对应。读模型更加面向于用户的读需求而设计,不需要和聚合对应。
线上出bug了,有一些读模型生成错了,怎么办?
最好是可以自动恢复的,比如事件消费失败,那么修复好bug后,会自动从失败的地方恢复执行。否则,只能人工介入去修复了。
新需要来了,要有新的读模型,如何初始化新的读模型?
如果新的读模型可以从老的领域事件计算出来,那就写个程序专门把历史的领域事件发给多模型生成程序,让它生成一遍就好。否则,得结合业务场景,考虑人工设置什么样的初始值比较合适了。
有一个查询功能,要重用领域模块的计算逻辑,怎么办?
尽量不要在读模型里做复杂的业务逻辑的计算,哪怕只是查询。
- 尽量在发布领域事件之前,把这样富有业务意义的数据先计算出来,这样查询模块直接拿来用就可以了。
- 把这样的计算逻辑封装到较为独立的值对象或领域服务中,然后在查询模块里去直接重用这个代码。
- 把这样的计算逻辑封装到一个单独的模块里,放到领域模块外部,领域模块通过以来翻转使用它,查询模块可以直接依赖它。